This entry asks what type of developer you are. White collar versus blue collar. What the question essentially comes down to is what level of education do you have. White collar developers are considered to have a four-year college or university degree while the blue collar developers have less education. So, are these degrees really necessary to become a software developer?
This question really needs to be in a less broad context. For instance, is it likely that as a developer you will need an advanced computer science degree to build typical web applications? Not likely. Will you need one to do optimization work with embedded software. Probably.
Computer scientists have the theoretical know-how that is an absolute must in certain circumstances. Other developers have more experience in what is the more practical way out of a given situation. The important thing to note, I think, is that either one has limitations. It is the job at hand that dictates who is best for the job.
In addition, not being able to produce a degree for highly niche jobs doesn't necessarily mean a road block for some developers. If you can show, through software that you have built in the past, the knowledge you have, it is a good alternative.
Thursday, November 26, 2009
Friday, November 20, 2009
Open Source Closure
Google has recently open-sourced it's javascript tools called Closure. It is this suite of tools that Google uses in every web application that it hosts. They claim to have made it available for download so that developers of other web applications have an opportunity to make the web faster as a whole. That sounds a bit to me like "hey, if you drop the javascript toolkit you are currently using and use ours, your application will be faster. yay!"
I don't necessarily buy it if that is the case. Sure, Google has nice, well-performing web applications that would certainly impress your customers if you could offer something similar. But this market is already flooded with good quality javasctipt toolkits. jQuery is tough to compete with for most intents and purposes.
One area that Closure has an advantage in is the fact that it is shipped with a javascript compiler, an area relatively unexplored. At most, the javascript of many application might be slightly compressed before it is served up to clients.
If you aren't already heavily invested in another javascript toolkit, closure may be worth looking at. If that, or any other kit for that matter, is the one you choose, stick with it. Don't mix and match javascript toolkits. You'll just be asking for trouble.
I don't necessarily buy it if that is the case. Sure, Google has nice, well-performing web applications that would certainly impress your customers if you could offer something similar. But this market is already flooded with good quality javasctipt toolkits. jQuery is tough to compete with for most intents and purposes.
One area that Closure has an advantage in is the fact that it is shipped with a javascript compiler, an area relatively unexplored. At most, the javascript of many application might be slightly compressed before it is served up to clients.
If you aren't already heavily invested in another javascript toolkit, closure may be worth looking at. If that, or any other kit for that matter, is the one you choose, stick with it. Don't mix and match javascript toolkits. You'll just be asking for trouble.
Wednesday, November 18, 2009
External Exception Handlers
Erica Naone has put together an interesting entry on new software called ClearView. The software was created by Martin Richard's research group at MIT.
The goal behind this software is to key a watchful eye on running applications. Now, these application would have to be of some significance, otherwise, it probably would be worth babysitting them to this extent. But for applications containing sensitive data, something like ClearView can be very helpful.
The idea behind ClearView is to analyze the behavior of a given program while it is behaving as expected. This allows ClearView to determine what the rules of good behavior for a particular application are. Once these rules are broken, ClearView knows that the application is misbehaving and can address it. The real nice thing is, the fixes are applied to the running binary, not the source code.
The best way to picture ClearView from a high level perspective is to picture the running application as a piece of protected code running inside an exception handler. Obviously, this isn't in the code, and, isn't even real for that matter. But, it is similar to what happens. ClearView goes beyond what typical exception handlers do. It tries to fix the problem rather than point fingers. Maybe exception handlers inside code could learn from ClearView in the future, or maybe not.
The goal behind this software is to key a watchful eye on running applications. Now, these application would have to be of some significance, otherwise, it probably would be worth babysitting them to this extent. But for applications containing sensitive data, something like ClearView can be very helpful.
The idea behind ClearView is to analyze the behavior of a given program while it is behaving as expected. This allows ClearView to determine what the rules of good behavior for a particular application are. Once these rules are broken, ClearView knows that the application is misbehaving and can address it. The real nice thing is, the fixes are applied to the running binary, not the source code.
The best way to picture ClearView from a high level perspective is to picture the running application as a piece of protected code running inside an exception handler. Obviously, this isn't in the code, and, isn't even real for that matter. But, it is similar to what happens. ClearView goes beyond what typical exception handlers do. It tries to fix the problem rather than point fingers. Maybe exception handlers inside code could learn from ClearView in the future, or maybe not.
Tuesday, November 17, 2009
Twisted System Events
One of the key features of the Twisted Python web framework is the ability to define reactors that react to asynchronous events. One concept of the the Twisted reactor is the system event. The ReactorBase class is inherited from all reactor types in Twisted, as the name suggests. It is this class that provides all other reactors with a system event processing implementation.
An event, in the context of the Twisted reactor system, has three phases, or states. These states are "before", "during", and "after". What this provides for developers is a means to conceptually organize triggers that are executed when a specific event is fired. The "before" state should execute triggers that are supposed to verify certain data, or perform setup tasks. Anything that would be considered a pre-condition is executed here. The "during" state is overall goal of the event. Triggers that are executed in this state should do the heavy processing. Conceptually, this is the main reason a trigger was registered to execute with the specified event type in the first place. Finally, the "after" state executes triggers that should perform post-condition testing, or clean-up type tasks.
Illustrated below are the various states that a Twisted system event will go through during its' lifetime. The transitions between states are quite straightforward. When there are no more triggers to execute for the current state, the next state is entered.

Event triggers are registered with specific event types by invoking the ReactorBase.addSystemEventTrigger() method. This method accepts an event state, callable, and event type parameters. The callable can be any callable Python object.
The type of event in which triggers can be registered to can be anything. The event type is only the key for a stored event instance. The _ThreePhaseEvent class is instantiated if not already part on the reactor. That is, if a trigger has already been registered for the same event type, that means an event instance has been created. The _ThreePhaseEvent instance for each event type is responsible for executing all event triggers in the correct order. Using the Twisted system event functionality means that dependencies between event states may be used to achieve desired functionality.
An event, in the context of the Twisted reactor system, has three phases, or states. These states are "before", "during", and "after". What this provides for developers is a means to conceptually organize triggers that are executed when a specific event is fired. The "before" state should execute triggers that are supposed to verify certain data, or perform setup tasks. Anything that would be considered a pre-condition is executed here. The "during" state is overall goal of the event. Triggers that are executed in this state should do the heavy processing. Conceptually, this is the main reason a trigger was registered to execute with the specified event type in the first place. Finally, the "after" state executes triggers that should perform post-condition testing, or clean-up type tasks.
Illustrated below are the various states that a Twisted system event will go through during its' lifetime. The transitions between states are quite straightforward. When there are no more triggers to execute for the current state, the next state is entered.

Event triggers are registered with specific event types by invoking the ReactorBase.addSystemEventTrigger() method. This method accepts an event state, callable, and event type parameters. The callable can be any callable Python object.
The type of event in which triggers can be registered to can be anything. The event type is only the key for a stored event instance. The _ThreePhaseEvent class is instantiated if not already part on the reactor. That is, if a trigger has already been registered for the same event type, that means an event instance has been created. The _ThreePhaseEvent instance for each event type is responsible for executing all event triggers in the correct order. Using the Twisted system event functionality means that dependencies between event states may be used to achieve desired functionality.
Monday, November 16, 2009
Calling All Objects
Python, being the object-oriented language that it is, provides developers with the ability to override the default behavior of classes. This includes the default operator behavior, or, operator-overloading. This is done in Python like operator-overriding. The default operator functionality for each operator has a corresponding method that may be overridden. I like this a lot as it isn't a big deal to completely change the face of a class in a couple hours should the need arise.
One of the more interesting ways one can customize the default class behavior provided by the language is to make instances of classes callable. An example of a callable object would be a function or a method. It is callable because it is a parametrized piece of behavior that can be invoked. The invoking context then supplies parameter values to this callable behavior.
Shown below is an example of how the __call__() method can be overridden to make instances callable.
Here, we have a simple Person class. This class defines a constructor that will set the two attributes of the class. The __call__() method will take any supplied keyword parameters and set them as attributes of the instance. The key aspect of this __call__() implementation to note is the fact that the instance itself is returned by the function. It is by doing this that we allow the state of the instance to be updated and retrieve the altered version of the instance in the same invocation. This is similar to having a setter type function return the instance. I like the callable instance approach simple because the concept is more prevalent in the code.
One of the more interesting ways one can customize the default class behavior provided by the language is to make instances of classes callable. An example of a callable object would be a function or a method. It is callable because it is a parametrized piece of behavior that can be invoked. The invoking context then supplies parameter values to this callable behavior.
Shown below is an example of how the __call__() method can be overridden to make instances callable.
#Example; Using __call__ to set attributes.
#Simple person class.
class Person(object):
#Constructor. Initialize attributes.
def __init__(self, first_name=None, last_name=None):
self.first_name=first_name
self.last_name=last_name
#Make Person instances callable. Set the provided
#attributes and return the modified instance.
def __call__(self, *args, **kw):
for attr in kw.keys():
setattr(self, attr, kw[attr])
return self
#Return a formatted string with the attribute values.
def format(self):
return "First Name: %s\nLast Name: %s"%\
(self.first_name, self.last_name)
#Main.
if __name__=="__main__":
#Construct a Person instance with initial attribute values.
print "Constructing..."
person_obj=Person(first_name="Joe", last_name="Blow")
#Display output.
print person_obj.format()
#Call the person object to fetch a modified version.
print "Updating..."
print person_obj(first_name="John", last_name="Smith").format()
Here, we have a simple Person class. This class defines a constructor that will set the two attributes of the class. The __call__() method will take any supplied keyword parameters and set them as attributes of the instance. The key aspect of this __call__() implementation to note is the fact that the instance itself is returned by the function. It is by doing this that we allow the state of the instance to be updated and retrieve the altered version of the instance in the same invocation. This is similar to having a setter type function return the instance. I like the callable instance approach simple because the concept is more prevalent in the code.
Friday, November 6, 2009
Django Cache Nodes
As part of the Django Python web application framework is a powerful template system. Many other Python web application frameworks rely on external template rendering packages whereas Django includes this functionality. Normally, it is a good idea to not re-invent the wheel an use existing functionality provided in other packages. Especially specialized packages that do only one thing like render templates. Django, however, is a batteries-included type of framework that doesn't really have external package dependencies.
The Django templating system is not all that different from other Python template rendering systems. It is quite straightforward for both developers and for UI designers to use.
Down at the code level, everything in a template is considered to be a node. In fact, there is a Node class that every template component inherits from. It could have been named TemplateComponent but that isn't the best name for a class. Node sounds better.
One type of node that may be found in Django templates is a cache node. These are template fragments that may be stored in the Django caching system once they have been rendered. Underlying these template cache nodes is the CacheNode class and is illustrated below.
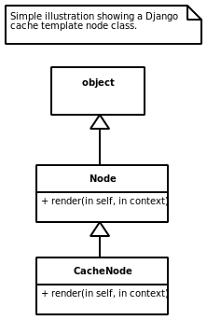
As mentioned, every Django template node type extends from the Node class and CacheNode is no different. Also, as is shown in the illustration, the render() method is overridden to provide the specific caching functionality.
Illustrated below is an activity depicting how the CacheNode.render() method will attempt to retrieve a cached version of the node that has already been rendered and return that value instead if possible.
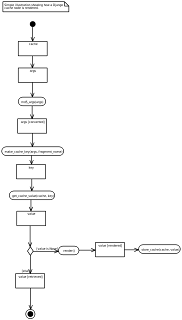
In this illustration, we start off with two objects, cache and args. The cache object represents the Django cache system as a whole. The args object is the context of the specific node about to be rendered. Next, the context is turned into an MD5 value. The reason for this is to produce a suitable value that can used to construct a cache key. Once this operation has completed, we now have a converted copy of the context. Next, we construct a cache key. This key serves as the query we submit to the Django cache system. Next, we perform the query, asking the cache system for a value based on the key we have just constructed. Finally, if a value was returned by the cache system, this is the rendered value that we return. If now value exists in the cache system, we now need to give it one. This means that we must render the node and pass the result to the cache system and also return this rendered value.
The Django templating system is not all that different from other Python template rendering systems. It is quite straightforward for both developers and for UI designers to use.
Down at the code level, everything in a template is considered to be a node. In fact, there is a Node class that every template component inherits from. It could have been named TemplateComponent but that isn't the best name for a class. Node sounds better.
One type of node that may be found in Django templates is a cache node. These are template fragments that may be stored in the Django caching system once they have been rendered. Underlying these template cache nodes is the CacheNode class and is illustrated below.

As mentioned, every Django template node type extends from the Node class and CacheNode is no different. Also, as is shown in the illustration, the render() method is overridden to provide the specific caching functionality.
Illustrated below is an activity depicting how the CacheNode.render() method will attempt to retrieve a cached version of the node that has already been rendered and return that value instead if possible.

In this illustration, we start off with two objects, cache and args. The cache object represents the Django cache system as a whole. The args object is the context of the specific node about to be rendered. Next, the context is turned into an MD5 value. The reason for this is to produce a suitable value that can used to construct a cache key. Once this operation has completed, we now have a converted copy of the context. Next, we construct a cache key. This key serves as the query we submit to the Django cache system. Next, we perform the query, asking the cache system for a value based on the key we have just constructed. Finally, if a value was returned by the cache system, this is the rendered value that we return. If now value exists in the cache system, we now need to give it one. This means that we must render the node and pass the result to the cache system and also return this rendered value.
Tuesday, November 3, 2009
File System Resources
RESTful web services often employ the concept of resources. When reading about RESTful web services, you will often here the term resource or resource-oriented. This is because a key principle of a RESTful system is that of the URI. The unique resource identifier is used to point to some resource, as the name suggests.
The concept of a unique resource identifier says nothing about the context in which it is used. That is, a URI can point to a resource on the web, or it can point to a resource locally on the file system. When using a URI on the local file system, the URIs will only be unique within the local context. For instance, the URI file:///home/ probably isn't unique within the context of the web but would most surely be unique within the local system.
There are two types of resources we are interested in when constructing RESTful applications. There are remote resource that the application might be interested in that live on the web. And, there are local resources the application might be interested in that exist locally within the file system. These two resource types really aren't all that different. The obvious difference of course being the context in which the resource is considered unique. The other difference is at a level lower than that of a RESTful design is how the actual IO functionality is implemented. For instance, you can't perform read operations on remote resource by invoking traditional file system functionality. The same is also true for performing read functionality with remote resources.
One of the similarities between remote resources and local resources is the URI. The URI differs only slightly between the remote resource, typically using HTTP as the protocol, and the local resource which uses a file IO protocol.
Illustrated below is a simple class hierarchy that models a flexible resource. It is flexible in the sense that instantiated resources can be either remote or local in the application.

Here, the base class is Protocol. Inheriting from this class is the base Resource class, with the children resources, File and HTTP. The classes are purposefully incomplete in definition because this hierarchy allows for many implementation variations. The Protocol class is high level and probably serves as an interface. The reason we want to define the Protocol class in the first place is that in this context, where resources may not be using the same protocol, resources may be considered a protocol type.
The Resource class is what should define the higher-level resource functionality. This is where the uniform methods that should be functional for any resource type should be defined. These could map closely to HTTP methods or to some other consistent interface. The File and HTTP class provide the lower level implementations that are invoked by the Resource interface. This enables an application to use resource abstractions, both local and remote, with no regard for context as the behavior can be invoked in a polymorphic way.
The concept of a unique resource identifier says nothing about the context in which it is used. That is, a URI can point to a resource on the web, or it can point to a resource locally on the file system. When using a URI on the local file system, the URIs will only be unique within the local context. For instance, the URI file:///home/ probably isn't unique within the context of the web but would most surely be unique within the local system.
There are two types of resources we are interested in when constructing RESTful applications. There are remote resource that the application might be interested in that live on the web. And, there are local resources the application might be interested in that exist locally within the file system. These two resource types really aren't all that different. The obvious difference of course being the context in which the resource is considered unique. The other difference is at a level lower than that of a RESTful design is how the actual IO functionality is implemented. For instance, you can't perform read operations on remote resource by invoking traditional file system functionality. The same is also true for performing read functionality with remote resources.
One of the similarities between remote resources and local resources is the URI. The URI differs only slightly between the remote resource, typically using HTTP as the protocol, and the local resource which uses a file IO protocol.
Illustrated below is a simple class hierarchy that models a flexible resource. It is flexible in the sense that instantiated resources can be either remote or local in the application.

Here, the base class is Protocol. Inheriting from this class is the base Resource class, with the children resources, File and HTTP. The classes are purposefully incomplete in definition because this hierarchy allows for many implementation variations. The Protocol class is high level and probably serves as an interface. The reason we want to define the Protocol class in the first place is that in this context, where resources may not be using the same protocol, resources may be considered a protocol type.
The Resource class is what should define the higher-level resource functionality. This is where the uniform methods that should be functional for any resource type should be defined. These could map closely to HTTP methods or to some other consistent interface. The File and HTTP class provide the lower level implementations that are invoked by the Resource interface. This enables an application to use resource abstractions, both local and remote, with no regard for context as the behavior can be invoked in a polymorphic way.
Subscribe to:
Posts
(
Atom
)